No hace falta soltar una pasta enorme ni comprar una plataforma cara desde el día uno. Yo prefiero un enfoque escalonado: comenzar con herramientas open source, montar una base sólida y demostrar valor en cada paso. Empezar por un caso de uso con impacto real, iterar y ampliar según vayamos madurando como equipo — así evitas gastar de más y además aprendes sobre la marcha.
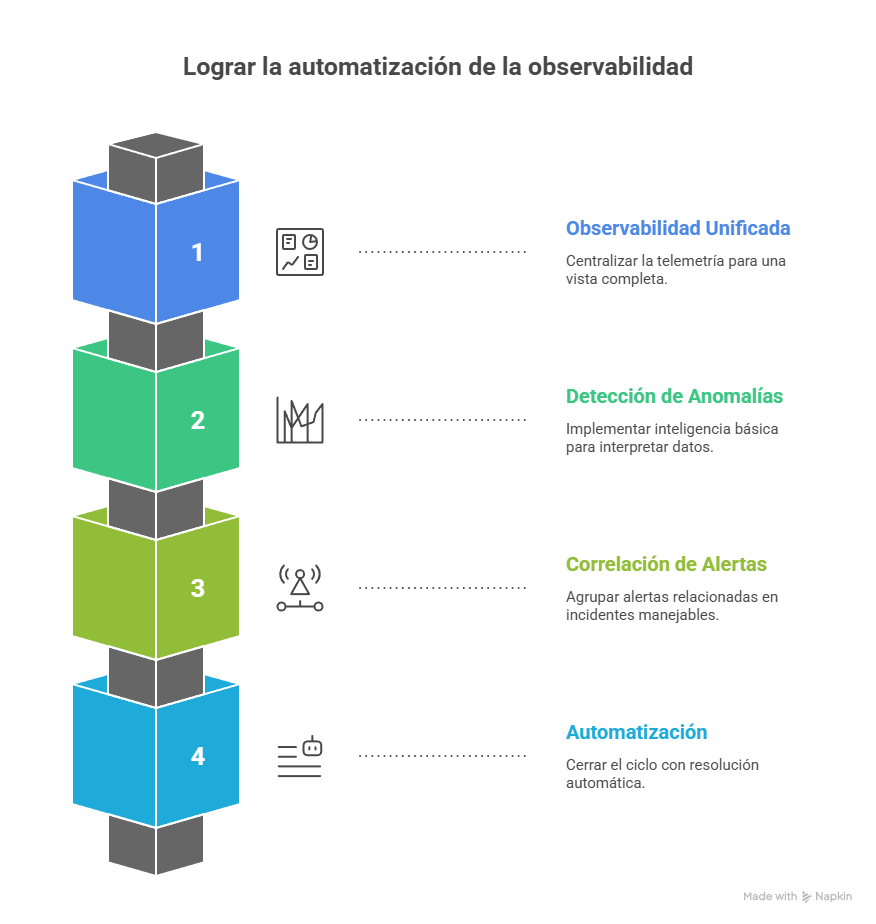
Fase 1 — La base: observabilidad única con el stack “PLG”
Lo primero es romper los silos: centralizar la telemetría para ver todo en conjunto. Sin esa observabilidad unificada, la IA no tiene nada con qué trabajar.
Qué hacer (práctico):
-
Prometheus para métricas. Yo recomiendo Prometheus como estándar para series temporales. Usa exporters (Node Exporter, JMX Exporter, etc.) para recoger métricas de infra y apps.
-
Loki para logs. Despliega Grafana Loki para almacenar logs de forma centralizada. Loki indexa etiquetas en vez del texto completo, así sale mucho más barato y es eficiente para grandes volúmenes.
-
Grafana para visualizar. Usa Grafana como ese “single pane of glass”. Monta dashboards que mezclen métricas de Prometheus y logs de Loki para que, por primera vez, el equipo pueda correlacionar eventos en la misma pantalla.
Fase 2 — Primeros pasos de IA: detección de anomalías en Grafana
Con los datos centralizados, toca darle una capa de inteligencia básica para que nos ayude a interpretarlos.
Qué hacer (práctico):
-
Plugin / modelos de ML en Grafana. Si usas Grafana Cloud/Enterprise, el plugin de ML trae detección de anomalías lista para usar. Si estás con la versión open source, puedes integrar modelos abiertos vía plugins o APIs.
-
Alertas dinámicas: en vez de umbrales estáticos (“CPU > 90%”), entrena modelos que aprendan el comportamiento “normal” (incluyendo estacionalidad diaria/semana). Luego dispara alertas solo cuando la métrica se salga claramente de su banda normal. Resultado: muchas menos falsas alarmas.
Fase 3 — Conectar los puntos: correlación de alertas
Aunque ya tengas detección inteligente, el ruido de alertas sigue siendo un problema. Aquí el objetivo es agrupar señales relacionadas en incidentes únicos y útiles.
Qué hacer (práctico):
-
Meter un gestor de alertas. Introduce una herramienta open source pensada para correlación, por ejemplo Keep.
-
Centralizar y agrupar. Envía Alertmanager y otras fuentes a Keep. Dentro de Keep define reglas que unan alertas por tiempo, contexto (mismo host, mismo servicio) o contenido; así muchas alertas pasan a ser un solo incidente manejable.
Fase 4 — El salto a la automatización: runbooks y auto-remediación
Aquí cerramos el ciclo: desde detectar hasta resolver automáticamente.
Qué hacer (práctico):
-
Definir triggers. Configura la herramienta de correlación para que, cuando aparezca un incidente claro (ej.: “servicio de autenticación no responde”), dispare un webhook o llamada a una API.
-
Invocar automatización. Ese trigger puede llamar a Ansible (o a un script en Python/PowerShell). La plataforma ejecuta un runbook predefinido: reiniciar un pod, limpiar caché, conmutar a un sistema secundario, etc.
Esto no es solo una hoja de ruta técnica; es un modelo de madurez. Partes de un estado reactivo (nivel 0), pasas a observabilidad centralizada (nivel 1), luego a análisis asistido por IA (nivel 2), consigues contexto con correlación (nivel 3) y, finalmente, llegas a automatización proactiva (nivel 4). La ventaja es que lo construyes por etapas, mostrando valor en cada una y controlando coste y riesgo.
En definitiva
Yo creo que la manera más sensata de avanzar con AIOps es empezar pequeño y con open source —montar primero una observabilidad sólida, añadir después detección inteligente, correlacionar alertas y, finalmente, automatizar solo aquello que realmente aporta valor. De ese modo reduces riesgos, cortas el ruido y vas mostrando resultados palpables mientras la solución madura.
¡Sigue, comenta y comparte!
Seguro que esto te interesa



