Si te soy sincero, mi día a día como administrador de sistemas ya no se parece a lo que era antes: ahora parece que vivo intentando apagar pequeños incendios en un bosque que no deja de crecer. Los entornos de TI han mutado —microservicios por aquí, contenedores por allá, nubes híbridas y multi-nube cruzándose— y con ello llegó una avalancha de datos operativos que abruma. El resultado: fatiga de alertas. Es decir, una lluvia interminable de notificaciones que vienen de decenas de herramientas distintas y que, la mayoría de las veces, no conectan entre sí.
La presión por encontrar el problema, diagnosticar la causa raíz y reducir el MTTR nunca ha sido tan grande. Y lo cierto es que las herramientas tradicionales se quedan cortas frente a este panorama.
Aquí es donde entra AIOps. No es una “caja mágica” ni una varita milagrosa; para mí es la evolución lógica y necesaria de las operaciones de TI. AIOps aplica de forma sistemática la inteligencia artificial y el machine learning para analizar toda esa marea de datos, automatizar tareas repetitivas y, sobre todo, devolvernos control y visibilidad sobre ecosistemas cada vez más complejos. En pocas palabras: nos ayuda a pasar de operaciones reactivas a proactivas, anticipando problemas antes de que afecten al negocio.
¿Qué es realmente AIOps y por qué debería importarte?
Antes de nada, conviene tener clara la definición y entender por qué esto dejó de ser una opción y se convirtió en una necesidad.
Definición clara y concisa
Gartner acuñó el término AIOps. Yo lo resumo así: es la aplicación de capacidades de IA —desde procesamiento de lenguaje natural hasta modelos de machine learning— para automatizar y agilizar los flujos de trabajo en operaciones de TI. Piensa en una plataforma AIOps como un asistente virtual para tu equipo: conoce el entorno y la red en contexto, analiza en tiempo real, sugiere acciones precisas e incluso puede ejecutar correcciones por sí misma. Es como tener a alguien que no duerme y que va filtrando la información útil del ruido.
¿Por qué ahora? — El punto de inflexión de la complejidad
La necesidad de AIOps no apareció de la nada; es la respuesta a una cadena de cambios que terminaron por colapsar los enfoques tradicionales. La transformación digital nos dio más poder —hardware y software mucho más capaces— pero también más complejidad. La adopción masiva de arquitecturas distribuidas (nube, microservicios, contenedores) disparó la cantidad y la velocidad de los datos que producimos: logs, métricas, trazas… una auténtica marea que, simplemente, un humano no puede abarcar.
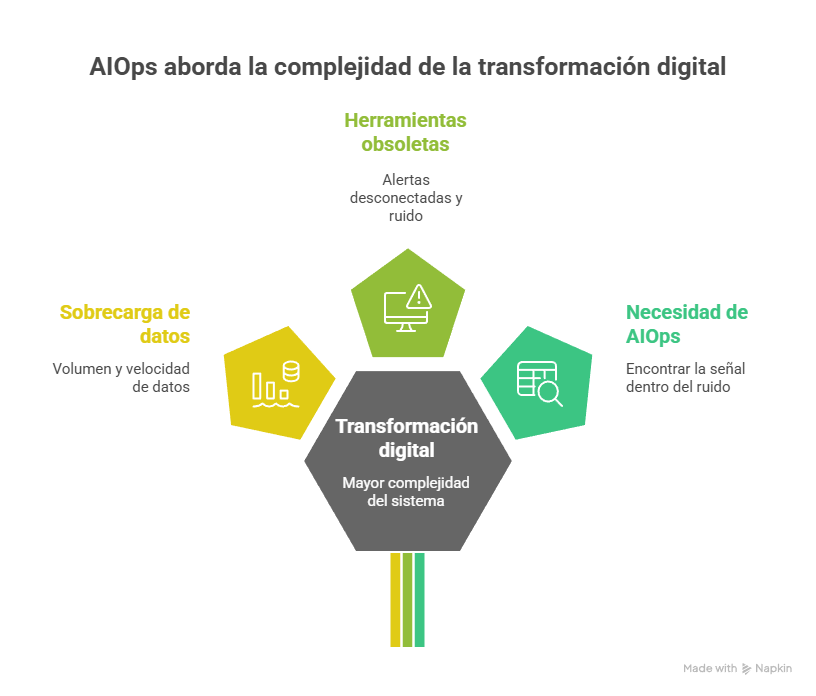
La cultura DevOps y la nube aceleraron la cadencia de despliegues y la efímera vida de muchos componentes; eso aumentó la volumen, variedad y velocidad de telemetría. Las herramientas tradicionales, con thresholds rígidos y funcionando en silos, se vieron desbordadas y empezaron a generar alertas desconectadas —mucho ruido, poca señal—.
AIOps nace para rellenar ese hueco: combina Big Data y machine learning para encontrar la señal dentro del ruido. Para alguien que administra sistemas, adoptar AIOps no es seguir una moda; es equiparse con las herramientas necesarias para manejar la realidad tecnológica que ya forma parte del trabajo diario.
La anatomía de una plataforma AIOps: un vistazo bajo el capó
Si quieres quitarle la aura de «caja negra» a AIOps, lo mejor es abrirla y ver cómo fluye la información. Yo siempre explico esto con un modelo simple de tres fases: Observar, Interactuar y Actuar. Es el mapa del viaje que hace cada dato, desde que nace hasta que se convierte en una acción que resuelve algo.
El flujo central: Observar → Interactuar → Actuar
Este triángulo describe cómo una plataforma AIOps transforma telemetría dispersa en decisiones operativas. No es ciencia ficción: es ingeniería aplicada para convertir ruido en contexto y contexto en acción.
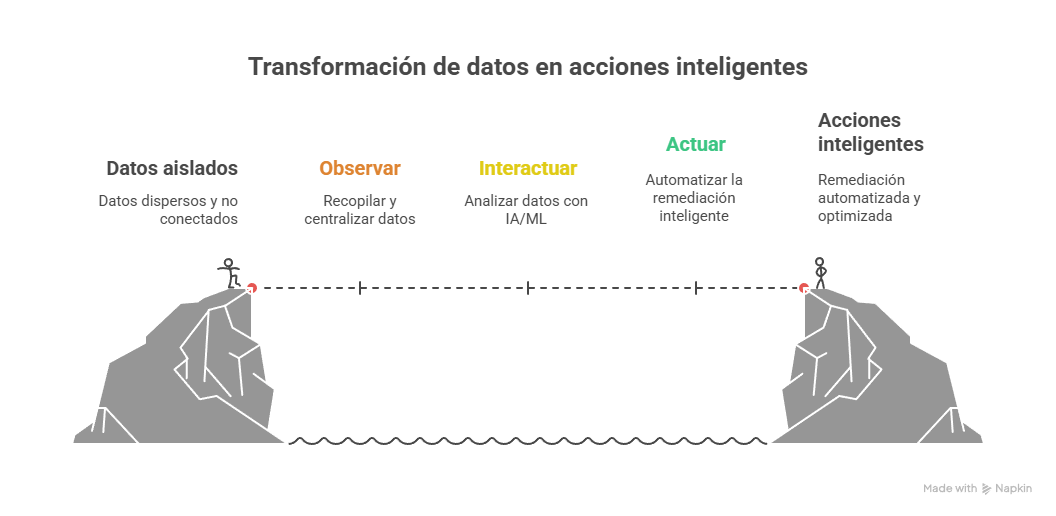
Fase 1 — Observar (ingesta y centralización de datos)
Lo primero y más importante es romper los silos. Si los datos siguen repartidos en ciento y un sistemas, AIOps no puede hacer su trabajo. Por eso la plataforma debe recoger y centralizar volúmenes enormes de información en una única capa de big data: una vista lo más completa y actual posible del estado de tu infraestructura.
Entre las fuentes que siempre incluyo cuando diseño una ingestión están:
-
Historiales de rendimiento y eventos.
-
Streams de eventos en tiempo real.
-
Logs y métricas del sistema.
-
Datos de red (sí, hasta paquetes cuando es necesario).
-
Tickets e incidencias.
-
Trazas e información de infraestructura.
Cuanto más contexto juntes, más fácil será que la siguiente fase saque conclusiones útiles.
Fase 2 — Interactuar (el “cerebro” de IA/ML)
Aquí sucede la parte que muchos llaman “magia”, pero que en realidad es análisis avanzado y modelos entrenados para detectar lo que un humano no puede ver a simple vista.
Las capacidades principales que ejecutan son:
-
Detección de patrones y anomalías: los modelos contrastan lo que está ocurriendo ahora con las líneas base históricas para señalar comportamientos extraños —a menudo mucho antes de que un umbral clásico se dispare.
-
Correlación de eventos: en vez de lanzarte mil alertas sueltas (CPU 95%, latencia subida, errores 503…), la plataforma agrupa los eventos relacionados en un único incidente con contexto. Menos ruido, más foco.
-
Inferencia y análisis de causa raíz (RCA): aquí no basta con juntar cosas; hay que entender dependencias y proponer la causa más probable del fallo.
Esto convierte montañas de datos en hipótesis accionables: no te promete certidumbre absoluta, pero sí prioridades claras y pistas fiables para investigar.
Fase 3 — Actuar (automatización y remediación inteligente)
El objetivo final es pasar del diagnóstico a la resolución, y si se puede, que sea automática. Los niveles de actuación suelen ordenarse así:
-
Notificación inteligente: en lugar de una alerta genérica, el sistema enruta el incidente (ya enriquecido con diagnóstico y contexto) a la persona o equipo adecuado, basándose en historial y especialización.
-
Remediación asistida: se presentan al operador runbooks sugeridos, pasos claros y evidencia que aceleran la resolución manual.
-
Auto-remediación: para problemas conocidos y repetitivos, la plataforma ejecuta scripts o flujos que resuelven el incidente sin tocar a nadie.
Y ojo: esto no es un proceso lineal. Es un ciclo de retroalimentación. Cada acción y su resultado (por ejemplo, si reiniciar un servicio arregló o no el problema) vuelve a integrarse como dato en la fase de Observar, alimentando y mejorando los modelos. Con el tiempo la plataforma aprende y se afina: no se queda igual, evoluciona.
El superpoder del sysadmin: beneficios prácticos de AIOps en tu día a día
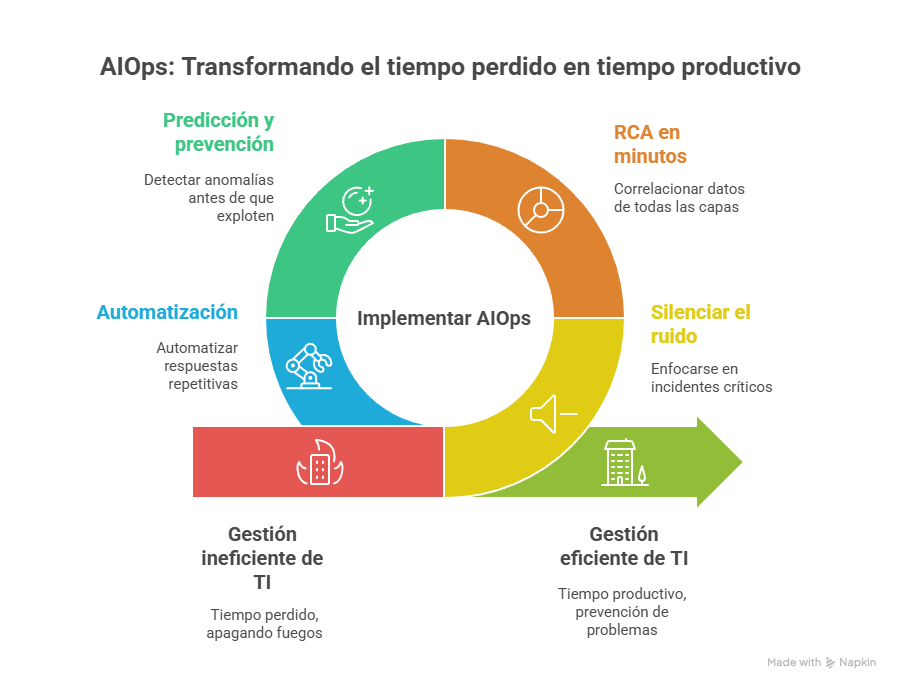
Si me preguntas por lo que realmente cambia AIOps en la vida diaria de un administrador, te diré: convierte tiempo perdido en tiempo productivo. Pasa de apagar fuegos a prevenirlos, y eso cambia todo el rol.
Beneficio 1 — Silenciar el ruido y enfocarte en lo crítico
La sobrecarga de alertas es realidad. AIOps reduce el ruido blanco agrupando cientos de señales sintomáticas en incidentes de alto nivel —por ejemplo, transformar “CPU al 95% + latencia + errores 503” en “problema en el servicio de pagos”. Resultado: menos pestañeos en Slack y más concentración en lo que importa.
Beneficio 2 — RCA en minutos, no en horas
Esto me ha salvado más de una vez: en vez de que redes, BD y apps trabajen en paralelo sin un hilo conductor, AIOps toma datos de todas las capas y los correlaciona. Un cambio de configuración hecho hace 15 minutos, una consulta lenta, y la degradación de UX se conectan en minutos. No es magia, es correlación contextual que acelera enormemente la investigación.
Beneficio 3 — Predicción y prevención
Lo que más me gusta: no esperar a que algo explote. Los modelos de anomalías pueden detectar, por ejemplo, una fuga de memoria lenta que hoy no es crítica pero mañana tumbará el servicio, o una tendencia de crecimiento del uso de disco que alcanzará el límite el fin de semana. Eso te permite actuar antes de que los usuarios se quejen.
Beneficio 4 — Automatización que te devuelve horas (auto-remediación)
Y llegamos al rendimiento real: automatizar respuestas repetitivas para que el equipo se dedique a mejorar la plataforma en vez de mantenerla a flote.
Algunos ejemplos prácticos que suelo implementar:
-
Escalado automático de recursos: si detectas un pico anómalo en tráfico, la plataforma lanza un runbook (por ejemplo con Ansible) que aprovisiona instancias y las añade al balanceador. El servicio aguanta sin intervención humana.
-
Reinicio inteligente de servicios: si un servicio falla, la plataforma intenta reiniciarlo; si después de dos intentos no funciona, crea un ticket de alta prioridad (Jira), adjunta logs y traces relevantes, y alerta al on-call vía PagerDuty o Slack.
-
Mantenimiento proactivo: si los modelos predicen que el disco de una base de datos llegará a tope en 48 horas, la plataforma puede purgar logs temporales y, a la vez, avisar al DBA para planear una ampliación a más largo plazo.
En definitiva
La verdad es que AIOps deja de ser una promesa para convertirse en una herramienta práctica: nos ayuda a transformar ese ruido insoportable en contexto útil, a encontrar la causa raíz más rápido y, sobre todo, a devolvernos tiempo para pensar en mejoras reales. Para mí, la mayor ganancia no es que la máquina “reemplaza” al administrador, sino que nos permite dejar de ser bomberos eternos y pasar a diseñar, anticipar y optimizar.
Además, es importante recordar que AIOps no es una varita mágica: requiere datos buenos, integración honesta y una dosis de paciencia. Pero, cuando se implementa bien, el ciclo observar→interactuar→actuar se convierte en un círculo virtuoso: cada remediación enseña al sistema y cada predicción evita un incidente. Con eso ganas menos estrés, menos noches en vela y más capacidad para hacer trabajo estratégico —y créeme, eso se nota en el día a día.
¡Sigue, comenta y comparte!
Seguro que esto te interesa



